Player Data Key Concepts #
In this topic, we’ll look at key concepts for creating your own player data features in Pragma Engine.
Player Data Service #
The Player Data service houses the structures and interfaces for building your own player data features. The service acts as a toolbox containing all the tools you can use to customize and integrate your player data feature into Pragma Engine. Since a feature can be designed for various different purposes, the Player Data service has endpoints for every type of gateway and data model for a player data feature.
Everything you author in the Player Data service is written in its own Maven module underneath the pre-existing 5-ext module in Pragma Engine. The Player Data service has a Maven module because the service uses reflection and code generation to streamline the process of writing customizable endpoints and data structures for a player data feature.
Code generation and reflection #
Pragma Engine uses protobuf definitions as the interface definition language (IDL) for serializing strongly typed data. The Player Data service, along with all other services in Pragma Engine, use protobufs for managing API endpoints and its corresponding data.
Instead of writing your endpoints in protos and Kotlin like a typical custom service, the Player Data service generates code you create in Kotlin into protobufs for the Pragma Engine layer. In other words, the interfaces utilized in the Player Data service to author your player data features reflect your code so you don’t have to write business logic in more than one language and in more than one place.
Modules #
The core of the Player Data service lies in the concept of a Player Data Module, which houses the Sub Service class for containing all the API endpoint logic (Operations), live data (Entities), and content data for a player data feature. Modules are designed to help organize and create maintainable code structures that the Player Data service can work with. For instance, when you design your own Player Data Module with Operations and data logic, the code you create will be generated into the larger Pragma Engine ecosystem and into the PragmaSDK for client use.
A Module can be designed for specific Player Data features like loadouts, battlepasses, and player ranks. It can also be designed to handle common events that occur throughout the lifecycle of a game or a player’s account history, such as granting rewards on account creation and season event gifts. Modules are able to access other Module Operations and data, so a player data feature can span across multiple different user-defined systems.
At a basic level, the real-time process of a player data feature in a Module works as follows:
A player activates a
RequestOperation on the game client side.The
RequestOperation contactsPlayerDataServiceto connect to the corresponding Module’sPlayerDataSubService, which contains all the logic for modifying the Player Data content from theRequestOperation.The
PlayerDataSubService’s Operation function then returns aResponsedefined by the developer based on the Operation function’s business logic so the client can respond accordingly.
All of the code you build for a player data feature will reside in a Player Data Module folder in 5-ext/ext-player-data/player-data/src/main/kotlin. In short, Player Data Modules house everything related to your player data feature, such as the feature’s respective endpoints, business logic, and data modeling.
Authoring API endpoints and data #
A player data feature must have defined API endpoints so the endpoint’s assigned gateway can communicate with the backend for data requests and updates. These endpoints in the Player Data service are called Operations and are responsible for creating, managing, and assigning live data and JSON content for players.
Operation Request and Response types for a player data feature are authored by the developer and are given business logic inside the Operation’s respective Sub Service class. By defining the Operations yourself, you get to perfectly contextualize your request and response endpoints with your player data feature and how they’ll handle player data content involved in the call.
All data in a Player Data Module is defined by the developer as Kotlin classes before being assigned in a Sub Service’s Operation. As the developer, you get to define the live data structures and game data schemas.
In the Player Data service, you can utilize two different data structures for authoring a feature’s data: Entity and PlayerDataContentSchema. Note that a Sub Service can utilize both of these structures in tandem or just one of them.
| Data Structures | Description |
|---|---|
Entity | A wrapper that contains live player data authored in Kotlin and saved in the database. |
PlayerDataContentSchema | A data class authored in Kotlin for structuring content as JSON catalogs. Every Sub Service has access to this interface and its user-defined content via the ContentLibrary class. |
Since the Player Data service allows for a lot of flexibility in how you design your player data feature, it’s important to know how to model your data workflow in a Player Data Sub Service.
Because all of the code you author for a Player Data Sub Service is generated and reflected, the way you define Sub Services, Operations and data must follow the Player Data service’s conventions to operate properly. For example, some conventions include Sub Service classes inheriting the PlayerDataSubService interface, and all Operations containing the same parameters for its respective Kotlin function.
To learn more about each of these specific conventions, check out the Task pages for other topics in Player Data.
Performance and scalability #
The Player Data service is responsible for the routing and networking layer for player data features, as well as the data persistence layer behind your business logic. This means that as the developer, you only have to manage the design of your player data features rather than their implementation and context within the backend structure.
When designing a feature in the Player Data service, all data is cached and stored in a database by Pragma Engine, and all player data updates are performed in one database transaction. This means that any error when updating the player’s data results in zero data changes, and no partial processes will occur. If there is an error in a database transaction, Pragma Engine logs the database error so you can see what went wrong.
It’s important to design your player data features to limit the rate of Operation and database calls made by game client and server to Pragma Engine. The Player Data service is designed to handle high loads and scale, but it’s important to make your Operation workflow in a Sub Service as optimal as possible. Additionally, you’ll have visibility into your Sub Services’ Operation traffic through metrics via Grafana panels.
PragmaSDK #
Everything that you author on the Kotlin side of a player data feature is auto-generated into protobufs for the engine layer and Unreal structs in the PragmaSDK for use on the client side. The generated Unreal structs belong to a Sub Service in the PragmaSDK and are generated based on their definitions on the Kotlin side. In other words, every Sub Service has its own generated API where each Operation maps to a usable API method.
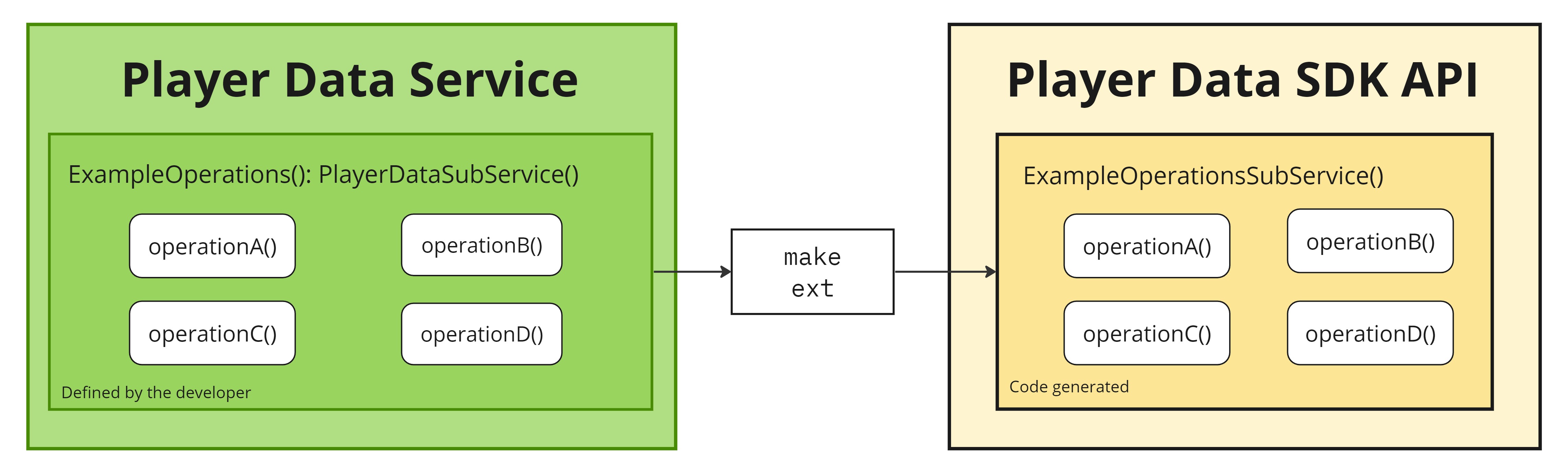
Since everything you author in the Player Data service is generated for the PragmaSDK, it’s also important to keep track of how you author your features in the backend, as they’ll directly affect how you interact with the service in the SDK.
%22/%3E%3Cpath%20d=%22M82%20113.698c1.821%201.063%201.834%202.78.0%203.843l-13.084%207.687a7.17%207.17.0%2001-3.284.798%207.17%207.17.0%2001-3.284-.798l-13.16-7.687c-1.821-1.063-1.834-2.78.0-3.843l13.084-7.687a7.168%207.168.0%20016.568.0L82%20113.698z%22%20fill=%22url(%23b)%22/%3E%3Cpath%20d=%22M73.16%20114.658a.985.985.0%2001.487.368%201.037%201.037.0%20010%201.186.981.981.0%2001-.486.369l-6.383%203.846a3.438%203.438.0%2001-3.198.0l-6.42-3.846a.982.982.0%2001-.486-.369%201.035%201.035.0%20010-1.186.986.986.0%2001.486-.368l6.383-3.846a3.438%203.438.0%20013.198.0l6.42%203.846z%22%20fill=%22%23fff%22/%3E%3Cpath%20d=%22M111%2048c-1.455-.642-37.943-12.532-45.55-14.5-7.607%202.022-43.495%2016.358-44.95%2017l37.504%2065.718c.106.239.291.435.524.556l5.542%203.209a3.038%203.038.0%20002.76.0l5.51-3.209c.25-.123.441-.338.535-.599L111%2048z%22%20fill=%22url(%23c)%22/%3E%3Cpath%20fill-rule=%22evenodd%22%20clip-rule=%22evenodd%22%20d=%22M109.533%2040.686c-6.925%203.665-17.69%203.562-24.4-.311-6.892-3.98-6.892-10.431.0-14.41%201.422-.822%203.026-1.473%204.737-1.955-17.595-6.637-41.42-5.496-56.87%203.424-17.72%2010.23-17.72%2026.815.0%2037.044%2017.719%2010.23%2046.447%2010.23%2064.167.0%2011.194-6.462%2015.316-15.461%2012.366-23.792z%22%20fill=%22url(%23d)%22/%3E%3Cg%20opacity=%22.7%22%20filter=%22url(%23e)%22%3E%3Ccircle%20r=%2237.046%22%20transform=%22scale(1.22477%20.70706)%20rotate(45%20-55.303%2098.057)%22%20fill=%22url(%23f)%22/%3E%3C/g%3E%3Cpath%20fill-rule=%22evenodd%22%20clip-rule=%22evenodd%22%20d=%22M96.321%2027.615a8.615%208.615.0%2001-2.019-.824c-2.848-1.644-2.848-4.31.0-5.954%201.296-.748%202.958-1.156%204.653-1.223a41.764%2041.764.0%2000-1.788-1.092c-17.72-10.23-46.448-10.23-64.168.0-17.72%2010.23-17.72%2026.814.0%2037.044s46.448%2010.23%2064.168.0c8.025-4.633%2012.416-10.57%2013.172-16.63-4.598%201.417-10.442%201.007-14.318-1.23-4.746-2.74-4.746-7.183.0-9.923.099-.057.199-.113.3-.168zm9.666-1.923a2.064%202.064.0%2001-.068.076l.139.01c-.023-.03-.047-.058-.071-.086z%22%20fill=%22url(%23g)%22/%3E%3Ccircle%20r=%222%22%20transform=%22matrix(.86604%20.49997%20-.86604%20.49997%2062.464%2051)%22%20fill=%22%23121212%22/%3E%3Ccircle%20r=%222%22%20transform=%22matrix(.86604%20.49997%20-.86604%20.49997%2081.464%2045)%22%20fill=%22%23121212%22/%3E%3Ccircle%20r=%222%22%20transform=%22matrix(.86604%20.49997%20-.86604%20.49997%2043.642%2031)%22%20fill=%22%23121212%22/%3E%3Ccircle%20r=%222%22%20transform=%22matrix(.86604%20.49997%20-.86604%20.49997%2039.464%2045)%22%20fill=%22%23121212%22/%3E%3Ccircle%20r=%222%22%20transform=%22scale(1.22477%20.70706)%20rotate(45%20-12.95%2084.623)%22%20fill=%22%23121212%22/%3E%3Ccircle%20r=%222%22%20transform=%22matrix(.86604%20.49997%20-.86604%20.49997%2062.464%2035)%22%20fill=%22%23121212%22/%3E%3Cdefs%3E%3ClinearGradient%20id=%22a%22%20x1=%2265.415%22%20y1=%22133.384%22%20x2=%2262.707%22%20y2=%22116.141%22%20gradientUnits=%22userSpaceOnUse%22%3E%3Cstop%20stop-color=%22%23bebebe%22/%3E%3Cstop%20offset=%221%22%20stop-color=%22%23fff%22/%3E%3C/linearGradient%3E%3ClinearGradient%20id=%22b%22%20x1=%2265.415%22%20y1=%22126.531%22%20x2=%2257.672%22%20y2=%22104.287%22%20gradientUnits=%22userSpaceOnUse%22%3E%3Cstop%20stop-color=%22%23bebebe%22/%3E%3Cstop%20offset=%221%22%20stop-color=%22%23fff%22/%3E%3C/linearGradient%3E%3ClinearGradient%20id=%22c%22%20x1=%2265.409%22%20y1=%22107.427%22%20x2=%2265.409%22%20y2=%2274.173%22%20gradientUnits=%22userSpaceOnUse%22%3E%3Cstop%20stop-color=%22%23fff%22%20stop-opacity=%22.72%22/%3E%3Cstop%20offset=%221%22%20stop-color=%22%23fff%22%20stop-opacity=%220%22/%3E%3C/linearGradient%3E%3ClinearGradient%20id=%22d%22%20x1=%2265.007%22%20y1=%2270.496%22%20x2=%2261.493%22%20y2=%22.477%22%20gradientUnits=%22userSpaceOnUse%22%3E%3Cstop%20stop-color=%22%23edf2f9%22/%3E%3Cstop%20offset=%221%22%20stop-color=%22%23fff%22%20stop-opacity=%220%22/%3E%3C/linearGradient%3E%3ClinearGradient%20id=%22f%22%20x1=%2270.425%22%20y1=%2221.274%22%20x2=%22-.284%22%20y2=%2248.41%22%20gradientUnits=%22userSpaceOnUse%22%3E%3Cstop%20stop-color=%22%231efff1%22/%3E%3Cstop%20offset=%221%22%20stop-color=%22%231548ff%22/%3E%3C/linearGradient%3E%3ClinearGradient%20id=%22g%22%20x1=%2220.05%22%20y1=%2263.78%22%20x2=%2255.07%22%20y2=%22-9.969%22%20gradientUnits=%22userSpaceOnUse%22%3E%3Cstop%20offset=%22.156%22%20stop-color=%22%231efff1%22/%3E%3Cstop%20offset=%221%22%20stop-color=%22%231548ff%22/%3E%3C/linearGradient%3E%3Cfilter%20id=%22e%22%20x=%224.71%22%20y=%226.763%22%20width=%22120.747%22%20height=%2282.388%22%20filterUnits=%22userSpaceOnUse%22%20color-interpolation-filters=%22sRGB%22%3E%3CfeFlood%20flood-opacity=%220%22%20result=%22BackgroundImageFix%22/%3E%3CfeBlend%20in=%22SourceGraphic%22%20in2=%22BackgroundImageFix%22%20result=%22shape%22/%3E%3CfeGaussianBlur%20stdDeviation=%227.5%22%20result=%22effect1_foregroundBlur%22/%3E%3C/filter%3E%3C/defs%3E%3C/svg%3E)